Cet article fournit une solution de système de diffusion vocale numérique Ethernet intégré, qui peut facilement réaliser la fonction de diffusion régionale du système de diffusion. Le système est basé sur l'architecture du bras et adopte le procédé d'arbitrage du terminal de lecture du système pour contrôler la réalisation de la diffusion régionale, et le contenu de diffusion peut être lu et enregistré simultanément.
Le système de diffusion vocale numérique Ethernet fait principalement référence au système de diffusion qui utilise Ethernet comme support de transmission pour fournir des services audio. Ethernet peut être utilisé pour résoudre le problème de la transmission longue distance de signaux vocaux. Permet aux concepteurs de créer une structure de réseau à grande échelle pour réaliser la transmission de milliers de signaux vocaux numériques sur Ethernet, en utilisant pleinement les ressources du réseau existantes, en évitant le problème de la configuration répétée des lignes et en réalisant l'intégration des réseaux de diffusion et informatiques . Il résout les problèmes de mauvaise qualité sonore, de sensibilité aux interférences, de maintenance et de gestion complexes et de mauvaise interaction dans les systèmes de radiodiffusion traditionnels. Dans le même temps, il est possible de sélectionner tout, une partie ou des zones spécifiques pour la radiodiffusion de groupe directionnelle, ce qui dépasse la limitation selon laquelle les systèmes de radiodiffusion traditionnels ne peuvent assurer la radiodiffusion publique que pour toutes les zones. Les systèmes de diffusion vocale numérique Ethernet existants utilisent principalement des signaux de commande pour commander au terminal de diffusion de rejoindre ou de quitter le groupe de multidiffusion en réalisant la fonction de diffusion régionale. Il est nécessaire d'envoyer un signal de commande pour que le terminal rejoigne le groupe de multidiffusion avant que la diffusion puisse être réalisée. , Ou établir une table de mappage complexe côté serveur pour maintenir l'état du terminal de lecture pour réaliser une diffusion régionale, ce qui est plus compliqué à mettre en œuvre.
1 Conception structurelle
Ce système adopte une structure C / S, est composé de deux parties de l'extrémité du serveur du système de diffusion et du terminal de diffusion du système de diffusion, comme le montre la figure 1.
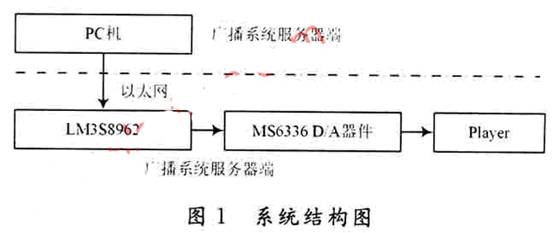
Le serveur du système de diffusion est implémenté sur un PC, et c'est un programme de collecte de signaux vocaux, de stockage et de transmission réseau réalisé par VC ++. Cette partie recueille et stocke le signal vocal via un microphone, puis transmet les données vocales à Ethernet via UDP pour réaliser la fonction de transmission réseau des données vocales.
Le terminal de lecture du système de diffusion est un terminal embarqué basé sur LM3S8962, qui peut recevoir les paquets de données vocales IP qui lui sont envoyés depuis Ethernet, et la puce de décodage audio MS6336 complète la conversion numérique / analogique et la lecture des données vocales.
2 Conception matérielle du terminal de diffusion du système de diffusion
La puce de contrôle principale du terminal de diffusion du système de diffusion adopte le microcontrôleur LM3S8962 fourni par LuminaryMicro. Cette série de puces est le premier contrôleur basé sur ARM CortexTM-M3 avec un contrôleur Ethernet intégré interne. Il s'agit de la première puce ARM du secteur qui prend en charge Industrial Ethernet (IEEE) et peut facilement implémenter des fonctions réseau.
La puce du décodeur audio utilise la puce MS6336 produite par MOSA. La puce est un convertisseur numérique-analogique audio stéréo 16 bits, et les formats d'entrée numérique pris en charge sont Justifl-ed droit, Justifié gauche, I2S. L'interface de contrôle MS6336 adopte le bus I2C, l'interface est facile à définir. La partie DAC a un courant précis et stable, combiné à une excellente méthode de décodage symétrique, peut reproduire des signaux audio de haute qualité.
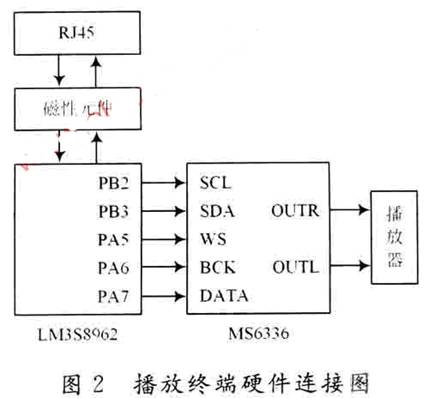
La puce de contrôle principale LM3S8962 est connectée à l'interface RJ45 via des composants magnétiques et est utilisée pour recevoir des données vocales d'Ethernet. LM3S8962 fournit des signaux de commande et des signaux de données vocales pour la puce de décodeur audio MS6336. LM3S8962 prend en charge la fonction I2C. Les ports PB2 et PB3 fournissent respectivement des signaux d'horloge et de données I2C. Ces deux broches peuvent être directement connectées aux broches de fonction I2C du MS6336 et une résistance de rappel est nécessaire. LM3S8962 ne prend pas en charge le format d'entrée de données requis par MS6336. Le format d'entrée de données du MS6336 dans le système adopte I2S. Par conséquent, pour fournir des données vocales au MS6336, il est nécessaire d'utiliser le logiciel de port GPIO du LM3S8962 pour simuler le format d'entrée de données I2S requis par MS6336. Dans la conception, les ports PA5, PA6 et PA7 sont utilisés pour simuler cette fonction. Les trois broches correspondent respectivement au signal de sélection de canal I2S, au signal d'horloge et au signal de données. Connectez ces trois broches à la broche de fonction I2S du MS6336.
La structure matérielle du terminal de lecture du système de diffusion vocale numérique Ethernet est illustrée à la figure 2.
3 Conception du logiciel du système de diffusion
Le logiciel du système de diffusion est divisé en deux parties: le logiciel serveur du système de diffusion et le logiciel du terminal de diffusion.
Cette conception réalise la lecture en temps réel des données vocales, de sorte que les performances en temps réel de la transmission de données vocales doivent être garanties, mais les exigences d'intégrité des données ne sont pas trop strictes et une petite quantité de perte de paquets n'affectera pas le effet de lecture global, de sorte que les données vocales du système La transmission adopte le mode de transmission UDP. En même temps, le système fonctionne dans le réseau local et il y a peu d'utilisateurs temporaires. Par conséquent, l'attribution d'adresse IP statique est adoptée pour simplifier la réalisation du logiciel du terminal de lecture.
3.1 La collecte, le stockage et la transmission de données vocales côté serveur du système de diffusion
La collecte de données vocales est mise en œuvre à l'aide des fonctions de l'API audio WAVE de bas niveau. Afin de ne pas provoquer de perte de données vocales, la conception utilise une double mise en mémoire tampon pour stocker les données vocales. Le processus de mise en œuvre est illustré à la figure 3.
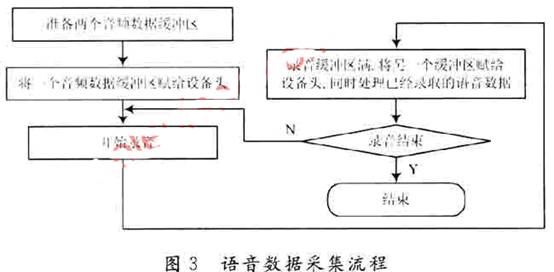
Lorsqu'un tampon d'enregistrement est plein, le système envoie immédiatement un autre tampon d'enregistrement à l'appareil d'enregistrement pour continuer l'enregistrement, et le programme d'application doit lire les données dans le tampon d'enregistrement complet et les traiter. Appelez ensuite la fonction waveInAddBuffer pour réaffecter le tampon à l'appareil d'enregistrement pour le recyclage.
Afin d'éviter la perte de données vocales lors du processus d'enregistrement, il ne suffit pas d'utiliser simplement un double tampon. Il convient également de noter que lorsqu'un tampon est plein, l'application traitera les données dans le tampon et le second Le tampon est utilisé pour l'enregistrement, et le temps de traitement des données doit être inférieur au temps nécessaire pour que le second tampon soit complètement enregistré, sinon le premier tampon n'a pas été réaffecté au dispositif d'enregistrement après que le second tampon est plein, ce qui entraînera une perte de données vocales. Lorsque la fréquence d'échantillonnage du signal vocal est élevée, augmenter la taille de la mémoire tampon de manière appropriée peut résoudre efficacement ce problème.
Afin de sauvegarder le contenu de diffusion pour une utilisation ultérieure, il est nécessaire de sauvegarder le contenu de diffusion dans un fichier WAV. Les fichiers WAV ont un format d'en-tête fixe. Avant d'enregistrer les données vocales, vous devez définir l'en-tête du fichier WAV, sinon le fichier WAV enregistré ne pourra pas être lu. Chaque fois que le tampon d'enregistrement est plein, recherchez d'abord la fin du fichier WAV, puis écrivez les données collectées à la fin du fichier à tour de rôle. Lorsque l'ensemble du processus de diffusion est terminé, toutes les données vocales sont enregistrées dans le fichier WAV, réalisant ainsi le stockage des données vocales.
Lorsqu'une mémoire tampon d'enregistrement est pleine, il est nécessaire d'envoyer les données vocales collectées via le réseau. Dans la conception, utilisez d'abord la classe Csocket pour créer un socket, puis il vous suffit d'encapsuler les données collectées dans un paquet IP et de l'envoyer. Le taux d'échantillonnage du signal vocal dans cette conception est de 44.1 kHz, 16 bits à double canal. Afin d'éviter la perte de données vocales, la taille du tampon d'enregistrement est fixée à 1024B.
3.2 Réalisation de la diffusion régionale
Une application importante du système de diffusion vocale numérique Ethernet n'est pas seulement de réaliser la diffusion de toute la zone, mais également de réaliser la fonction de diffusion locale, c'est-à-dire de diffuser vers le terminal désigné. Par conséquent, le paquet de multidiffusion UDP est utilisé pour la transmission de données dans la transmission réseau de paquets de données IP vocales. En utilisant des paquets de multidiffusion pour transmettre des données, tous les terminaux inclus dans le groupe dans le réseau local peuvent recevoir les données, réalisant la diffusion de la zone entière. Afin de réaliser la fonction de diffusion locale, une structure est ajoutée devant les données vocales dans la conception, comme illustré ci-dessous, et un fichier de configuration est utilisé pour stocker l'adresse IP de chaque terminal du système.
02 Conception matérielle du terminal de diffusion du système de radiodiffusion
La puce de contrôle principale du terminal de diffusion du système de diffusion adopte le microcontrôleur LM3S8962 fourni par LuminaryMicro. Cette série de puces est le premier contrôleur basé sur ARM CortexTM-M3 avec un contrôleur Ethernet intégré interne. Il s'agit de la première puce ARM du secteur qui prend en charge Industrial Ethernet (IEEE) et peut facilement implémenter des fonctions réseau.
La puce du décodeur audio utilise la puce MS6336 produite par MOSA. La puce est un convertisseur numérique-analogique audio stéréo 16 bits, et les formats d'entrée numérique pris en charge sont Justifl-ed droit, Justifié gauche, I2S. L'interface de contrôle MS6336 adopte le bus I2C, l'interface est facile à définir. La partie DAC a un courant précis et stable, combiné à une excellente méthode de décodage symétrique, peut reproduire des signaux audio de haute qualité.
La puce de contrôle principale LM3S8962 est connectée à l'interface RJ45 via des composants magnétiques et est utilisée pour recevoir des données vocales d'Ethernet. LM3S8962 fournit des signaux de commande et des signaux de données vocales pour la puce de décodeur audio MS6336. LM3S8962 prend en charge la fonction I2C. Les ports PB2 et PB3 fournissent respectivement des signaux d'horloge et de données I2C. Ces deux broches peuvent être directement connectées aux broches de fonction I2C du MS6336 et une résistance de rappel est nécessaire. LM3S8962 ne prend pas en charge le format d'entrée de données requis par MS6336. Le format d'entrée de données du MS6336 dans le système adopte I2S. Par conséquent, pour fournir des données vocales au MS6336, il est nécessaire d'utiliser le logiciel de port GPIO du LM3S8962 pour simuler le format d'entrée de données I2S requis par MS6336. Dans la conception, les ports PA5, PA6 et PA7 sont utilisés pour simuler cette fonction. Les trois broches correspondent respectivement au signal de sélection de canal I2S, au signal d'horloge et au signal de données. Connectez ces trois broches à la broche de fonction I2S du MS6336.
La structure matérielle du terminal de lecture du système de diffusion vocale numérique Ethernet est illustrée à la figure 2.
3 Conception du logiciel du système de diffusion
Le logiciel du système de diffusion est divisé en deux parties: le logiciel serveur du système de diffusion et le logiciel du terminal de diffusion.
Cette conception réalise la lecture en temps réel des données vocales, de sorte que les performances en temps réel de la transmission de données vocales doivent être garanties, mais les exigences d'intégrité des données ne sont pas trop strictes et une petite quantité de perte de paquets n'affectera pas le effet de lecture global, de sorte que les données vocales du système La transmission adopte le mode de transmission UDP. En même temps, le système fonctionne dans un réseau local avec moins d'utilisateurs temporaires. Par conséquent, l'attribution d'adresse IP statique est adoptée pour simplifier la réalisation du logiciel du terminal de lecture.
3.1 La collecte, le stockage et la transmission de données vocales côté serveur du système de diffusion
La collecte de données vocales est mise en œuvre à l'aide des fonctions de l'API audio WAVE de bas niveau. Afin de ne pas provoquer de perte de données vocales, la conception utilise une double mise en mémoire tampon pour stocker les données vocales. Le processus de mise en œuvre est illustré à la figure 3.
Lorsqu'un tampon d'enregistrement est plein, le système envoie immédiatement un autre tampon d'enregistrement à l'appareil d'enregistrement pour continuer l'enregistrement, et le programme d'application doit lire les données dans le tampon d'enregistrement complet et les traiter. Appelez ensuite la fonction waveInAddBuffer pour réaffecter le tampon à l'appareil d'enregistrement pour le recyclage.
Afin d'éviter la perte de données vocales lors du processus d'enregistrement, il ne suffit pas d'utiliser simplement un double tampon. Il convient également de noter que lorsqu'un tampon est plein, l'application traitera les données dans le tampon et le second Le tampon est utilisé pour l'enregistrement, et le temps de traitement des données doit être inférieur au temps nécessaire pour que le second tampon soit complètement enregistré, sinon le premier tampon n'a pas été réaffecté au dispositif d'enregistrement après que le second tampon est plein, ce qui entraînera une perte de données vocales. Lorsque la fréquence d'échantillonnage du signal vocal est élevée, augmenter la taille de la mémoire tampon de manière appropriée peut résoudre efficacement ce problème.
Afin de sauvegarder le contenu de diffusion pour une utilisation ultérieure, il est nécessaire de sauvegarder le contenu de diffusion dans un fichier WAV. Les fichiers WAV ont un format d'en-tête fixe. Avant d'enregistrer les données vocales, vous devez définir l'en-tête du fichier WAV, sinon le fichier WAV enregistré ne pourra pas être lu. Chaque fois que le tampon d'enregistrement est plein, recherchez d'abord la fin du fichier WAV, puis écrivez les données collectées à la fin du fichier à tour de rôle. Lorsque l'ensemble du processus de diffusion est terminé, toutes les données vocales sont enregistrées dans le fichier WAV, réalisant ainsi le stockage des données vocales.
Lorsqu'une mémoire tampon d'enregistrement est pleine, il est nécessaire d'envoyer les données vocales collectées via le réseau. Dans la conception, utilisez d'abord la classe Csocket pour créer un socket, puis il vous suffit d'encapsuler les données collectées dans un paquet IP et de l'envoyer. Le taux d'échantillonnage du signal vocal dans cette conception est de 44.1 kHz, 16 bits à double canal. Afin d'éviter la perte de données vocales, la taille du tampon d'enregistrement est fixée à 1024B.
3.2 Réalisation de la diffusion régionale
Une application importante du système de diffusion vocale numérique Ethernet n'est pas seulement de réaliser la diffusion de toute la zone, mais également de réaliser la fonction de diffusion locale, c'est-à-dire de diffuser vers le terminal désigné. Par conséquent, le paquet de multidiffusion UDP est utilisé pour la transmission de données dans la transmission réseau de paquets de données IP vocales. En utilisant des paquets de multidiffusion pour transmettre des données, tous les terminaux inclus dans le groupe dans le réseau local peuvent recevoir les données, réalisant la diffusion de la zone entière. Afin de réaliser la fonction de diffusion locale, une structure est ajoutée devant les données vocales dans la conception, comme illustré ci-dessous, et un fichier de configuration est utilisé pour stocker l'adresse IP de chaque terminal du système.
structure STRING
{Chaîne IPNO1;
Chaîne IPNO2;
...
Chaîne IPNO9;
Chaîne IPNO10};
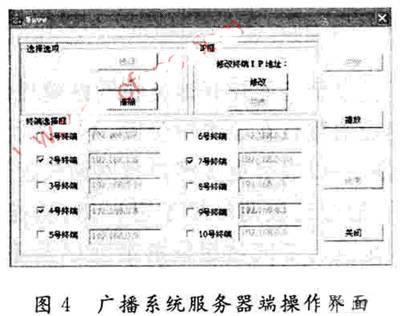
Lorsqu'il est nécessaire d'effectuer une diffusion régionale sur certains terminaux, sélectionnez les numéros correspondants de ces terminaux sur le panneau du côté serveur du système de diffusion (comme illustré sur la figure 4). À ce moment, l'adresse IP du terminal sélectionné est lue dans le fichier de configuration et affectée à la variable correspondante dans la structure. Lorsque le terminal reçoit un paquet IP multicast, il juge d'abord si la structure a la même variable que sa propre adresse IP, s'il y en a une, alors les données sont reçues et lues, sinon, les données sont rejetées, réalisant ainsi la zone de diffusion une fonction. Par rapport au procédé d'utilisation d'un signal de commande pour commander au terminal de lecture de rejoindre ou de quitter le groupe de multidiffusion, ou de maintenir dynamiquement une table de mappage complexe pour mettre en œuvre la fonction de diffusion régionale. Cette méthode n'a pas besoin de contrôler de manière interactive le terminal de lecture avant chaque diffusion, ni de suivre dynamiquement l'état du terminal. Il suffit d'écrire l'adresse IP correspondante du terminal dans le fichier de configuration lorsque le terminal rejoint le système pour la première fois. La fonction est simple à implémenter.
3.3 La réalisation du logiciel du terminal de diffusion du système de diffusion
Le terminal de diffusion du système de diffusion est divisé en deux parties à réaliser, la partie de réception de données audio est utilisée pour recevoir les données vocales et stocker et transmettre, et le décodeur audio réalise la conversion N / A et la lecture du signal vocal. La partie de réception de données audio adopte la programmation Socket pour recevoir des données vocales d'Ethernet. Après avoir reçu le paquet de données vocales, il doit d'abord juger si le paquet de données est pour lui-même. Le terminal compare la variable membre de la structure struct STRING dans le paquet IP avec sa propre adresse IP, et si une variable membre est égale à sa propre adresse IP, il stocke les données dans le paquet, sinon la rejette.
Les données vocales sont reçues et stockées dans une file d'attente circulaire. En raison du désordre de la transmission des données UDP, les paquets de données vocales doivent être triés après la réception des données vocales à l'extrémité de réception des données vocales pour assurer le traitement séquentiel des données vocales et la restauration correcte du signal vocal. Dans le même temps, afin d'éviter la gigue du réseau, les données sont traitées à chaque fois qu'il y a au moins 5 paquets dans la file d'attente circulaire.
Le format d'entrée de données du MS6336 dans la conception adopte le format I2S. Étant donné que LM3S8962 ne prend pas en charge ce format de données, la simulation logicielle est adoptée pour réaliser la fonction I2S via le port GPIO. Afin de restaurer complètement le signal vocal, il est nécessaire de s'assurer que la synchronisation du signal I2S est stricte et précise, et que la conversion entre les niveaux haut et bas est mise en œuvre par un programme de retard. Le chronogramme I2S est illustré à la figure 5.
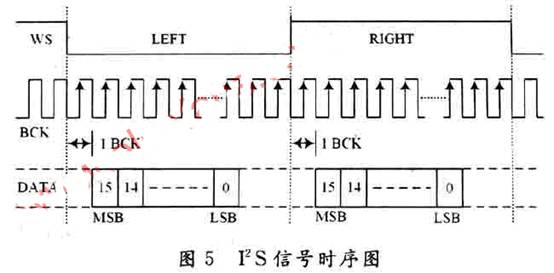
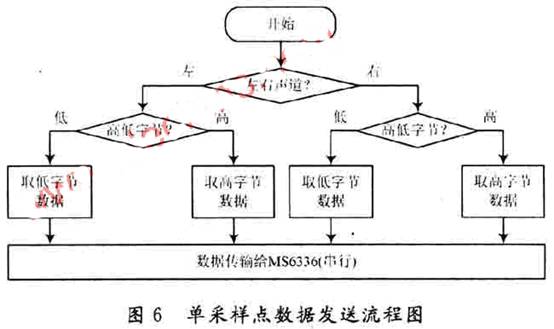
La fréquence d'horloge du terminal de diffusion du système de diffusion est de 40 MHz et le temps d'envoi de chaque bit de données est de 600 ns calculé à partir de la fréquence d'échantillonnage. Le LM3S8962 fournit des données vocales au MS6336 et réalise une transmission série via le port GPIO en fonction du point d'échantillonnage. Chaque point d'échantillonnage contient quatre octets et le processus d'envoi de données d'un point d'échantillonnage est illustré à la figure 6.
4 Analyse des résultats
La taille du paquet de données vocales transmis par le système via Ethernet est de 1024B. Afin d'éviter l'instabilité du réseau, le terminal commence à diffuser lors de la réception de 5 paquets de données. Le temps de retard de diffusion est d'environ 30 ms, ce qui correspond aux indicateurs fonctionnels. Le côté serveur peut contrôler le travail de 10 terminaux de diffusion en même temps. En sélectionnant le numéro de terminal correspondant du côté serveur, toutes les fonctions de diffusion de zone et de diffusion locale du système de diffusion peuvent être réalisées avec succès.
Conclusion 5
En partant des besoins réels, nous concevons et implémentons un système de diffusion vocale numérique Ethernet. Les résultats expérimentaux montrent que le terminal de lecture du système décide s'il faut effectuer une diffusion vocale pour réaliser une diffusion régionale est un moyen simple et efficace de réaliser une diffusion mondiale et une diffusion régionale de signaux vocaux. Le terminal du lecteur système adopte la simulation logicielle du port GPIO pour réaliser la fonction I2S, qui peut réaliser avec précision la synchronisation I2S, terminer la transmission de données du signal vocal et réaliser la diffusion en temps réel du signal vocal. La structure de conception est raisonnable et peut facilement réaliser l'expansion des fonctions, telles que la diffusion de synchronisation, la lecture de musique, la gestion à distance, la surveillance en temps réel, etc. systèmes.
Notre autre produit:












