Lorsque nous utilisons des outils tels que Skype et QQ pour mener en douceur des conversations vocales et vidéo avec des amis, nous sommes-nous déjà demandé quelles technologies puissantes se cachent derrière ? Cet article donnera une brève introduction aux technologies utilisées dans les appels vocaux en réseau, qui peuvent être considérées comme un aperçu du léopard.
1. Modèle conceptuel
Les appels vocaux Internet sont généralement bidirectionnels, ce qui est symétrique au niveau du modèle. Par souci de simplicité, nous pouvons discuter du canal dans un sens. Une partie parle et l'autre partie entend la voix. Cela semble simple et rapide, mais le processus sous-jacent est assez compliqué.
Il s'agit du modèle le plus basique composé de cinq liens importants : l'acquisition, l'encodage, la transmission, le décodage et la lecture.
(1) Collecte de voix
La collecte vocale fait référence à la collecte de données audio à partir d'un microphone, c'est-à-dire la conversion d'échantillons sonores en signaux numériques. Il fait intervenir plusieurs paramètres importants : la fréquence d'échantillonnage, le nombre de bits d'échantillonnage et le nombre de canaux.
Pour faire simple: la fréquence d'échantillonnage est le nombre d'actions d'acquisition en 1 seconde; le nombre de bits d'échantillonnage est la longueur des données obtenues pour chaque action d'acquisition.
La taille d'une trame audio est égale à : (fréquence d'échantillonnage × nombre de bits d'échantillonnage × nombre de canaux × temps)
Habituellement, la durée d'une trame d'échantillonnage est de 10 ms, c'est-à-dire que toutes les 10 ms de données constituent une trame audio. En supposant : le taux d'échantillonnage est de 16 k, le nombre de bits d'échantillonnage est de 16 bits et le nombre de canaux est de 1, alors la taille d'une trame audio de 10 ms est : (16000*16*1*0.01)/8 = 320 octets. Dans la formule de calcul, 0.01 est une seconde, c'est-à-dire 10 ms.
(2) Codage
En supposant que nous envoyions la trame audio collectée directement sans encodage, nous pouvons alors calculer la bande passante requise. Toujours l'exemple ci-dessus : 320*100 = 32 Ko/s, si converti en bits/s, c'est 256 Ko/s. C'est beaucoup d'utilisation de la bande passante. Avec les outils de surveillance du trafic réseau, nous pouvons constater que lorsque les appels vocaux sont passés avec un logiciel de messagerie instantanée comme QQ, le trafic est de 3 à 5 Ko/s, ce qui est un ordre de grandeur inférieur au trafic d'origine. Cela est principalement dû à la technologie de codage audio. Par conséquent, dans l'application d'appel vocal proprement dite, ce lien de codage est indispensable. Il existe de nombreuses technologies de codage de la parole couramment utilisées, telles que G.729, iLBC, AAC, SPEEX, etc.
(3) Transmission réseau
Lorsqu'une trame audio est encodée, elle peut être envoyée à l'appelant via le réseau. Pour les applications en temps réel telles que les conversations vocales, la faible latence et la stabilité sont très importantes, ce qui nécessite que notre réseau transmette de manière très fluide.
(4) Décodage
Lorsque l'autre partie reçoit la trame encodée, elle la décode pour la restituer en données pouvant être lues directement par la carte son.
(5) Lecture vocale
Une fois le décodage terminé, la trame audio obtenue peut être soumise à la carte son pour la lecture. Pièce jointe : vous pouvez vous référer à l'introduction et au code source de la démo et au téléchargement du SDK de MPlayer, un composant de lecture vocale
2. Difficultés et solutions dans les applications pratiques
Si seule la technologie mentionnée ci-dessus permet de réaliser un système de dialogue solide appliqué au réseau étendu, alors il n'est pas vraiment nécessaire d'écrire cet article. C'est précisément que de nombreux facteurs réalistes ont introduit de nombreux défis pour le modèle conceptuel mentionné ci-dessus, ce qui rend la réalisation du système vocal en réseau pas si simple, ce qui implique de nombreuses technologies professionnelles. Bien sûr, la plupart de ces défis ont déjà des solutions matures. Tout d'abord, nous devons définir un système de dialogue vocal "à bon effet". Je pense qu'il devrait atteindre les points suivants:
(1) Faible latence. Ce n'est qu'avec une faible latence que les deux parties à l'appel peuvent avoir un sens aigu du temps réel. Bien entendu, cela dépend principalement de la vitesse du réseau et de la distance entre les emplacements physiques des deux parties à l'appel. Du point de vue du logiciel pur, la possibilité d'optimisation est très faible.
(2) Faible bruit de fond.
(3) Le son est lisse, sans sensation de blocage ou de pause.
(4) Il n'y a pas de réponse.
Ci-dessous, nous parlerons des technologies supplémentaires utilisées dans le système de dialogue vocal réseau actuel une par une.
1. Annulation d'écho AEC Presque tout le monde est maintenant habitué à utiliser directement la fonction de lecture vocale sur PC ou ordinateur portable pendant le chat vocal. Comme tout le monde le sait, cette petite habitude a posé un grand défi pour la technologie vocale. Lors de l'utilisation de la fonction haut-parleur, le son joué par le haut-parleur sera à nouveau capté par le microphone et retransmis à l'autre partie, afin que celle-ci puisse entendre son propre écho. Par conséquent, dans les applications pratiques, la fonction d'annulation d'écho est nécessaire. Une fois la trame audio collectée obtenue, cet écart avant codage est le temps de fonctionnement du module d'annulation d'écho. Le principe est simplement que le module d'annulation d'écho effectue des opérations de type annulation dans la trame audio collectée en fonction de la trame audio qui vient d'être jouée, de manière à supprimer l'écho de la trame collectée. Ce processus est assez compliqué et est également lié à la taille de la pièce dans laquelle vous vous trouvez lorsque vous discutez et à votre emplacement dans la pièce, car cette information détermine la longueur de la réflexion des ondes sonores. Le module d'annulation d'écho intelligent peut ajuster dynamiquement les paramètres internes pour s'adapter au mieux à l'environnement actuel.
2. Suppression du bruit DENOISE La suppression du bruit, également connue sous le nom de traitement de réduction du bruit, est basée sur les caractéristiques des données vocales pour identifier la partie du bruit de fond et la filtrer hors des trames audio. De nombreux encodeurs ont cette fonctionnalité intégrée.
3. JitterBuffer Le tampon de gigue est utilisé pour résoudre le problème de gigue du réseau. La gigue du réseau signifie que le délai du réseau sera de plus en plus petit. Dans ce cas, même si l'expéditeur envoie régulièrement des paquets de données (par exemple, un paquet est envoyé toutes les 100 ms), le destinataire ne peut pas recevoir le même timing. Parfois, aucun paquet ne peut être reçu dans un cycle, et parfois plusieurs paquets sont reçus dans un cycle. De cette façon, le son que le récepteur entend est une carte une carte. JitterBuffer fonctionne après le décodeur et avant la lecture vocale. C'est-à-dire qu'une fois le décodage vocal terminé, la trame décodée est placée dans le JitterBuffer, et lorsque le rappel de lecture de la carte son arrive, la trame la plus ancienne est récupérée du JitterBuffer pour la lecture. La profondeur de tampon de JitterBuffer dépend du degré de gigue du réseau. Plus la gigue du réseau est importante, plus la profondeur de la mémoire tampon est grande et plus le délai de lecture audio est important. Par conséquent, JitterBuffer utilise un délai plus élevé en échange d'une lecture sonore fluide, car par rapport à la carte son une carte, un délai légèrement plus important mais un effet plus fluide, son expérience subjective est meilleure. Bien entendu, la profondeur de tampon de JitterBuffer n'est pas constante, mais ajustée dynamiquement en fonction des changements du degré de gigue du réseau. Lorsque le réseau est restauré pour être très fluide et non obstrué, la profondeur du tampon sera très faible, de sorte que l'augmentation du délai de lecture due au JitterBuffer sera négligeable.
4. Détection de sourdine VAD Dans une conversation vocale, si un interlocuteur ne parle pas, aucun trafic ne sera généré. La détection de sourdine est utilisée à cette fin. La détection de sourdine est généralement également intégrée dans le module d'encodage. L'algorithme de détection silencieuse combiné à l'algorithme de suppression de bruit précédent peut identifier s'il y a actuellement une entrée vocale. S'il n'y a pas d'entrée vocale, il peut coder et sortir une trame codée spéciale (par exemple, la longueur est 0). Surtout dans une vidéoconférence à plusieurs personnes, généralement une seule personne parle. Dans ce cas, l'utilisation de la technologie de détection silencieuse pour économiser de la bande passante est encore très importante.
5. Algorithme de mixage Dans un chat vocal à plusieurs personnes, nous devons lire les données vocales de plusieurs personnes en même temps et la carte son ne joue qu'un seul tampon. Par conséquent, nous devons mélanger plusieurs voix en une seule. C'est ce que fait l'algorithme de mixage. Même si vous pouvez trouver un moyen de contourner le mixage et de laisser plusieurs sons jouer en même temps, alors pour l'annulation d'écho, il doit être mélangé en une seule lecture, sinon, l'annulation d'écho ne peut éliminer qu'une partie des sons multiples à les plus. Tout le. Le mixage peut être effectué côté client ou côté serveur (ce qui permet d'économiser de la bande passante en aval). Si des canaux P2P sont utilisés, le mixage ne peut être effectué que du côté client. S'il mixe sur le client, le mixage est généralement le dernier lien avant de jouer. Cet article est un résumé approximatif de notre expérience dans la mise en œuvre de la partie vocale de l'OMCS. Ici, nous venons de faire une description simple de chaque lien de la figure, et chacun d'entre eux peut être écrit dans un long papier ou même dans un livre. Par conséquent, cet article est juste pour fournir une carte d'introduction pour ceux qui sont nouveaux dans le développement de systèmes vocaux en réseau, et donner quelques indices.



|
|
|
|
Dans quelle mesure (long) le couvercle du transmetteur?
La portée de transmission dépend de nombreux facteurs. La distance réelle est basée sur l'antenne d'installer la hauteur, le gain de l'antenne, en utilisant l'environnement comme la construction et d'autres obstacles, la sensibilité du récepteur, l'antenne du récepteur. Installation de l'antenne plus élevée et l'utilisation dans la campagne, la distance sera beaucoup plus loin.
Transmetteur FM 5W Exemple d'utilisation dans la ville et ville natale:
J'ai une utilisation par le client 5W émetteur fm USA avec antenne GP dans sa ville natale, et il le tester avec une voiture, il couvre 10km (6.21mile).
Je teste l'émetteur fm 5W avec antenne GP dans ma ville natale, il couvre environ 2km (1.24mile).
Je teste l'émetteur fm 5W avec antenne GP dans la ville de Guangzhou, il couvre environ seulement 300meter (984ft).
Voici la gamme approximative de différents émetteurs de puissance FM. (La plage est de diamètre)
Transmetteur FM 0.1W ~ 5W: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
Transmetteur FM 15W ~ 80W: 3KM ~ 10KM
Transmetteur FM 80W ~ 500W: 10KM ~ 30KM
Transmetteur FM 500W ~ 1000W: 30KM ~ 50KM
Transmetteur FM 1KW ~ 2KW: 50KM ~ 100KM
Transmetteur FM 2KW ~ 5KW: 100KM ~ 150KM
Transmetteur FM 5KW ~ 10KW: 150KM ~ 200KM
Comment nous contacter pour l'émetteur?
Appelez-moi + 8618078869184 OU
Envoyez-moi un courriel [email protected]
1.How loin que vous voulez couvrir de diamètre?
2.How haut de la tour vous?
3.Where êtes-vous?
Et nous allons vous donner plus de conseils professionnels.
À propos de nous
FMUSER.ORG est une société d’intégration de systèmes spécialisée dans la transmission sans fil RF / équipement audio vidéo / de studio / streaming et le traitement de données. Nous fournissons tout ce que vous souhaitez, du conseil au conseil en passant par l’intégration en rack, l’installation, la mise en service et la formation.
Nous proposons des émetteurs FM, des émetteurs de télévision analogique, des émetteurs de télévision numérique, des émetteurs VHF UHF, des antennes, des connecteurs de câble coaxial, STL, Traitement en direct, Produits de diffusion pour le studio, Surveillance du signal RF, Encodeurs RDS, Processeurs audio et Unités de contrôle de site distant, Les produits IPTV, encodeur / décodeur vidéo / audio, sont conçus pour répondre aux besoins des grands réseaux de diffusion internationaux et des petites stations privées.
Notre solution comprend une station de radio FM / une station de télévision analogique / une station de télévision numérique / un équipement de studio audio vidéo / une liaison d'émetteur de studio / un système de télémétrie d'émetteur / un système de télévision d'hôtel / une diffusion en direct IPTV / une diffusion en direct en continu / une conférence vidéo / un système de diffusion CATV.
Nous utilisons des produits de technologie de pointe pour tous les systèmes, car nous savons que la fiabilité et les performances élevées sont essentielles pour le système et la solution. Dans le même temps, nous devons également nous assurer que notre système de produits a un prix très raisonnable.
Nous avons des clients de diffuseurs publics et commerciaux, d'opérateurs de télécommunication et d'autorités de régulation, et nous proposons également des solutions et des produits à des centaines de diffuseurs plus petits, locaux et communautaires.
FMUSER.ORG exporte depuis plus de 15 ans et a des clients partout dans le monde. Avec 13 ans d'expérience dans ce domaine, nous avons une équipe professionnelle pour résoudre toutes sortes de problèmes du client. Nous nous sommes engagés à fournir des prix extrêmement raisonnables de produits et services professionnels. Email du contact : [email protected]
Notre Usine

Nous avons modernisation de l'usine. Vous êtes invités à visiter notre usine lorsque vous venez en Chine.

À l'heure actuelle, il existe déjà clients 1095 partout dans le monde visité notre bureau de Guangzhou Tianhe. Si vous venez en Chine, vous êtes invités à nous rendre visite.
Au Salon

Ceci est notre participation à 2012 Global Sources Hong Kong Electronics Fair . Les clients de partout dans le monde enfin avoir une chance de se réunir.
Où est Fmuser?
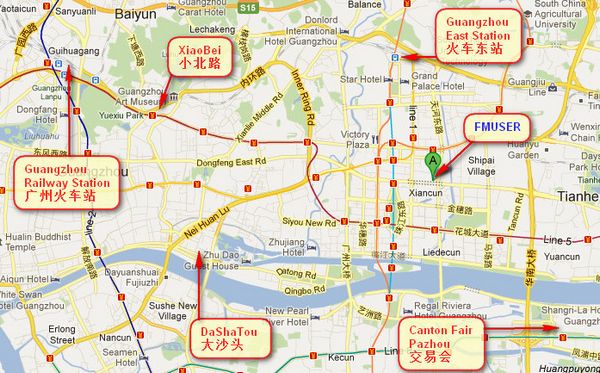
Vous pouvez rechercher ces numéros " 23.127460034623816,113.33224654197693 "dans google map, vous pouvez trouver notre bureau fmuser.
bureau FMUSER Guangzhou se trouve dans le district de Tianhe, qui est le centre du Canton . Très près à la Foire de Canton , gare de guangzhou, route Xiaobei et Dashatou , seul besion 10 minutes si prendre TAXIS . Bienvenue amis partout dans le monde à visiter et à négocier.
Contact: Blue Sky
Mobile: + 8618078869184
WhatsApp: + 8618078869184
WeChat: + 8618078869184
Courriel : [email protected]
QQ: 727926717
Skype: sky198710021
Adresse: No.305 Chambre Huilan bâtiment No.273 Huangpu route Guangzhou Chine Code postal: 510620
|
|
|
|
Français: Nous acceptons tous les paiements, tels que PayPal, carte de crédit, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer, si vous avez des questions, veuillez me contacter [email protected] ou WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Nous vous recommandons d'utiliser Paypal pour acheter nos articles, Le Paypal est un moyen sûr d'acheter sur Internet.
Chaque de notre liste d'articles en bas de page sur le dessus ont un logo paypal pour payer.
Carte de crédit.Si vous ne disposez pas paypal, mais vous avez la carte de crédit, vous pouvez également cliquer sur le bouton jaune PayPal pour payer avec votre carte de crédit.
-------------------------------------------------- -------------------
Mais si vous avez pas une carte de crédit et ne pas avoir un compte paypal ou difficile à obtenu un accout paypal, vous pouvez utiliser ce qui suit:
Western union.  www.westernunion.com www.westernunion.com
Paiement par Western Union à moi:
Prénom / Prénom: Yingfeng
Nom / Prénom / Nom de famille: Zhang
Nom complet: Yingfeng Zhang
Pays: Chine
Ville: Guangzhou
|
-------------------------------------------------- -------------------
T / T. Payer par T / T (virement / transfert télégraphique / Virement bancaire)
PREMIÈRES INFORMATIONS BANCAIRES (COMPTE COMPTE) :
SWIFT BIC: BKCHHKHHXXX
Nom de la banque: BANK OF CHINA (HONG KONG) LIMITÉE, HONG KONG
Adresse de la banque: BANK OF CHINA TOWER, 1 GARDEN ROAD, CENTRAL, HONG KONG
CODE DE LA BANQUE: 012
Nom du compte: FMUSER INTERNATIONAL GROUP LIMITED
N ° de compte. : 012-676-2-007855-0
-------------------------------------------------- -------------------
Deuxième RENSEIGNEMENTS BANCAIRES (COMPTE) :
Bénéficiaire : Fmuser International Group Inc
Numéro de compte: 44050158090900000337
Banque du bénéficiaire : succursale de la China Construction Bank Guangdong
Code SWIFT : PCBCCNBJGDX
Adresse : NO.553 Tianhe Road, Guangzhou, Guangdong, district de Tianhe, Chine
** Remarque : lorsque vous transférez de l'argent sur notre compte bancaire, veuillez ne rien écrire dans la zone de remarque, sinon nous ne pourrons pas recevoir le paiement en raison de la politique du gouvernement sur le commerce international.
|
|
|
|
* Il sera envoyé en 1-2 jours ouvrables lorsque le paiement clair.
* Nous vous enverrons à votre adresse paypal. Si vous voulez changer l'adresse, s'il vous plaît envoyez votre adresse et le numéro de téléphone à mon email [email protected]
* Si les paquets est inférieur à 2kg, nous sera expédiée par la poste aérienne, il faudra environ 15-25days à votre main.
Si le paquet est plus que 2kg, nous expédions par EMS, DHL, UPS, Fedex livraison rapide express, il faudra environ 7 ~ 15days à votre main.
Si le paquet plus 100kg, nous vous ferons parvenir par DHL ou fret aérien. Il faudra environ 3 ~ 7days à votre main.
Tous les paquets sont la forme la Chine guangzhou.
* Le colis sera envoyé comme un "cadeau" et déclear le moins possible, l'acheteur n'a pas besoin de payer pour la "TAXE".
* Après bateau, nous vous enverrons un e-mail et vous donner le numéro de suivi.
|
|
|
Pour la garantie.
Contactez-nous --- >> Renvoyez-nous l'article --- >> Recevez et envoyez un autre remplacement.
Nom: Liu xiaoxia
Adresse: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou en Chine.
Code postal: 510620
Téléphone: 8618078869184 XNUMX XNUMX XNUMX XNUMX
S'il vous plaît revenir à cette adresse et écrivez votre paypal adresse, nom, problème sur la note: |
|













