(1) Informations redondantes du signal vidéo
Prenant comme exemple le format de composant YUV d'enregistrement vidéo numérique, YUV représente respectivement la luminosité et deux signaux de différence de couleur. Par exemple, pour le système pal TV existant, la fréquence d'échantillonnage du signal de luminance est de 13.5 MHz; la bande de fréquence du signal de chrominance est généralement la moitié ou moins du signal de luminosité, qui est de 6.75 mhz ou 3.375 mhz. En prenant la fréquence d'échantillonnage de 4: 2: 2 comme exemple, le signal Y adopte 13.5 mhz, le signal de chrominance U et V sont échantillonnés à 6.75 mhz et le signal d'échantillonnage est quantifié par 8 bits, puis le taux de code de la vidéo numérique peut être calculé comme suit:
13.5 * 8 + 6.75 * 8 + 6.75 * 8 = 216 Mbit / s
Si une telle quantité de données est stockée ou transmise directement, il sera difficile d'utiliser la technologie de compression pour réduire le débit binaire. Le signal vidéo numérique peut être compressé selon deux conditions de base:
L. redondance des données. Par exemple, la redondance spatiale, la redondance temporelle, la redondance de structure, la redondance d'entropie d'information, etc., c'est-à-dire qu'il existe une forte corrélation entre les pixels de l'image. L'élimination de ces redondances n'entraîne pas de perte d'informations et il s'agit d'une compression sans perte.
L. redondance visuelle. Certaines caractéristiques des yeux humains, telles que le seuil de discrimination de la luminosité, le seuil visuel, sont différentes en sensibilité à la luminosité et à la chrominance, ce qui rend impossible l'introduction d'erreurs appropriées dans le codage et ne sera pas détectée. Les caractéristiques visuelles des yeux humains peuvent être utilisées pour échanger contre la compression de données avec une certaine distorsion objective. Cette compression est avec perte.
La compression du signal vidéo numérique est basée sur les deux conditions ci-dessus, ce qui rend les données vidéo fortement compressées, ce qui est propice à la transmission et au stockage. Les méthodes courantes de compression vidéo numérique sont le codage mixte, qui consiste à combiner le codage par transformée, l'estimation de mouvement et la compensation de mouvement, et le codage entropique pour compresser le codage. Habituellement, le codage par transformée est utilisé pour éliminer la redondance intra-trame de l'image, et l'estimation de mouvement et la compensation de mouvement sont utilisées pour supprimer la redondance inter-trame de l'image, et le codage entropique est utilisé pour améliorer encore l'efficacité de la compression. Les trois méthodes de codage de compression suivantes sont présentées brièvement.
(a) Méthode de codage par compression
(b) Codage par transformation
La fonction du codage par transformée est de transformer le signal d'image décrit dans le domaine spatial en domaine fréquentiel, puis de coder les coefficients transformés. D'une manière générale, l'image a une forte corrélation dans l'espace, et la transformation dans le domaine fréquentiel peut réaliser une décorrélation et une concentration d'énergie. La transformée orthogonale commune comprend la transformée de Fourier discrète, la transformée en cosinus discrète et ainsi de suite. La transformation en cosinus discrète est largement utilisée dans la compression vidéo numérique.
La transformée en cosinus discrète est appelée transformée DCT. Il peut transformer le bloc d'image de L * l du domaine spatial au domaine fréquentiel. Par conséquent, dans le processus de compression d'image et de codage basé sur DCT, l'image doit être divisée en blocs d'image ne se chevauchant pas. Supposons que la taille d'une image soit de 1280 * 720, elle est divisée en 160 * 90 blocs d'image avec une taille de 8 * 8 sans chevauchement sous forme de grille. Ensuite, la transformation DCT peut être effectuée pour chaque bloc d'image.
Une fois le bloc divisé, chaque bloc d'image 8 * 8 points est envoyé au codeur DCT, et le bloc d'image 8 * 8 est transformé du domaine spatial au domaine fréquentiel. La figure ci-dessous montre un exemple d'un bloc d'image de 8 * 8 dans lequel le nombre représente la valeur de luminosité de chaque pixel. On peut voir sur la figure que les valeurs de luminosité de chaque pixel dans ce bloc d'image sont relativement uniformes, en particulier la valeur de luminosité des pixels adjacents n'est pas très grande, ce qui indique que le signal d'image a une forte corrélation.
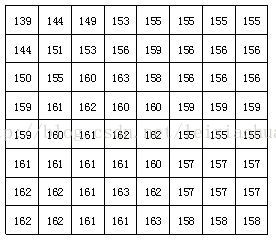
Un bloc d'image réel 8 * 8
La figure suivante montre les résultats de la transformation DCT du bloc d'image dans la figure ci-dessus. On peut voir sur la figure qu'après la transformation DCT, le coefficient basse fréquence dans le coin supérieur gauche concentre beaucoup d'énergie, tandis que l'énergie sur le coefficient haute fréquence dans le coin inférieur droit est très faible.
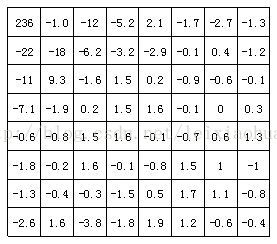
Les coefficients du bloc d'image après transformation DCT
Le signal doit être quantifié après la transformation DCT. Parce que les yeux humains sont sensibles aux caractéristiques basse fréquence des images, telles que la luminosité globale des objets, et non aux détails haute fréquence de l'image, donc dans le processus de transmission, les informations haute fréquence peuvent être transmises moins ou pas, seulement la partie basse fréquence. Le processus de quantification réduit la transmission d'informations en quantifiant les coefficients de la région basse fréquence et la quantification grossière des coefficients dans la région haute fréquence, ce qui supprime les informations haute fréquence qui ne sont pas sensibles aux yeux humains. Par conséquent, la quantification est un processus de compression avec perte et la principale raison des dommages de qualité dans le codage de compression vidéo.
Le processus de quantification peut être exprimé par la formule suivante:

Parmi eux, FQ (U, V) représente le coefficient DCT après quantification; f (U, V) représente le coefficient DCT avant quantification; Q (U, V) représente la matrice de pondération de quantification; q est l'étape de quantification; round fait référence à la consolidation et la valeur à afficher est considérée comme la valeur entière la plus proche.
Sélectionnez le coefficient de quantification de manière raisonnable, et le résultat après la quantification du bloc d'image transformé est affiché sur la figure.

Coefficient DCT après quantification
La plupart des coefficients DCT sont modifiés à 0 après la quantification, tandis que seuls quelques coefficients sont des valeurs non nulles. À ce stade, seules ces valeurs non nulles doivent être compressées et codées.
(b) Codage de l'entropie
Le codage d'entropie est nommé parce que la longueur moyenne du code après le codage est proche de la valeur d'entropie de la source. Le codage d'entropie est implémenté par VLC (codage à longueur variable). Le principe de base est de donner un code court au symbole avec une probabilité élevée dans la source, et de donner un code long au symbole avec une faible probabilité d'occurrence, de manière à obtenir statistiquement la longueur de code moyenne la plus courte. Le codage à longueur variable comprend généralement le code Hoffman, le code arithmétique, le code d'exécution, etc. Le codage de longueur d'exécution est une méthode de compression très simple, son efficacité de compression n'est pas élevée, mais la vitesse de codage et de décodage est rapide, et il est encore largement utilisé, en particulier après la transformation du codage, en utilisant le codage par longueur d'exécution, a un bon effet.
Premièrement, le coefficient AC immédiatement après le coefficient DC de sortie du quantificateur doit être balayé en type Z (comme indiqué dans la ligne de flèche). Le balayage Z transforme le coefficient de quantification bidimensionnel en une séquence unidimensionnelle, puis poursuit le codage de longueur de série. Enfin, un autre code de longueur variable est utilisé pour coder les données après le codage d'exécution, tel que le codage Hoffman. Grâce à ce type de codage à longueur variable, l'efficacité du codage est encore améliorée.
(c) Estimation de mouvement et compensation de mouvement
L'estimation de mouvement et la compensation de mouvement sont des méthodes efficaces pour éliminer la corrélation de la direction temporelle des séquences d'images. Les procédés de transformation DCT, de quantification et de codage par entropie décrits ci-dessus sont basés sur une image de trame. Grâce à ces méthodes, la corrélation spatiale entre les pixels de l'image peut être éliminée. En fait, en plus de la corrélation spatiale, le signal d'image a une corrélation temporelle. Par exemple, pour une vidéo numérique avec un arrière-plan statique comme la diffusion simultanée de nouvelles et un petit mouvement du corps principal de l'image, la différence entre chaque image est très petite et la corrélation entre les images est très grande. Dans ce cas, nous n'avons pas besoin de coder chaque image de trame séparément, mais nous pouvons seulement coder les parties modifiées des trames vidéo adjacentes, afin de réduire davantage la quantité de données. Ce travail est réalisé par estimation de mouvement et compensation de mouvement.
La technologie d'estimation de mouvement divise généralement l'image d'entrée actuelle en plusieurs petits sous-blocs d'image qui ne se chevauchent pas, par exemple, la taille d'une image de trame est de 1280 * 720. Premièrement, elle est divisée en blocs d'image de 40 * 45 avec 16 * 16 tailles qui ne se chevauchent pas sous forme de grille, puis, dans le cadre d'une fenêtre de recherche de l'image précédente ou de cette dernière image, trouvez un bloc pour chaque bloc d'image pour trouver un bloc d'image dans le cadre d'un fenêtre de recherche Le bloc d'image le plus similaire. Le processus de recherche est appelé estimation de mouvement. En calculant les informations de position entre le bloc d'image le plus similaire et le bloc d'image, un vecteur de mouvement peut être obtenu. De cette manière, le bloc d'image courant peut être soustrait du bloc d'image le plus similaire pointé par le vecteur de mouvement d'image de référence, et un bloc d'image résiduel peut être obtenu. Du fait que chaque valeur de pixel dans le bloc d'image résiduelle est très petite, un taux de compression plus élevé peut être obtenu dans le codage de compression. Ce processus de soustraction est appelé compensation de mouvement.
Étant donné que l'image de référence doit être utilisée pour l'estimation de mouvement et la compensation de mouvement dans le processus de codage, il est très important de sélectionner l'image de référence. Généralement, le codeur divise chaque image de trame entrée en trois types différents selon les différentes images de référence: trame I (intra), trame B (prédiction de guidage) et trame P (prédiction). Comme le montre la figure.
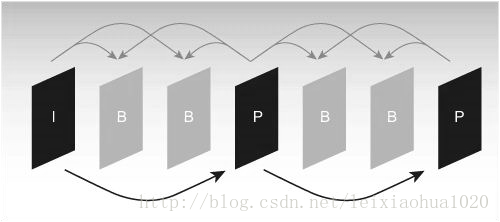
Séquence de structure de trame I, B, P typique
Comme le montre la figure, la trame I utilise uniquement les données de la trame pour le codage, et elle n'a pas besoin d'estimation de mouvement et de compensation de mouvement pendant le processus de codage. Evidemment, comme I frame n'élimine pas la corrélation de la direction du temps, le taux de compression est relativement faible. Dans le processus de codage, la trame P utilise une trame I avant ou une trame P comme image de référence pour la compensation de mouvement, en fait, elle code la différence entre l'image courante et l'image de référence. Le mode de codage de la trame B est similaire à la trame P, la seule différence est qu'il doit utiliser une trame I avant ou une trame P et une trame I ou P ultérieure pour prédire pendant le processus de codage. Ainsi, chaque codage de trame P doit utiliser une image de trame comme image de référence, tandis que la trame B a besoin de deux trames comme référence. En revanche, la trame B a un taux de compression plus élevé que la trame P.
(d) Codage mixte
Cet article présente plusieurs méthodes importantes de compression et de codage vidéo. Dans l'application pratique, ces méthodes ne sont pas séparées et sont généralement combinées pour obtenir le meilleur effet de compression. La figure suivante montre le modèle de codage hybride (c'est-à-dire codage par transformée + estimation de mouvement et compensation de mouvement + codage entropique). Le modèle est largement utilisé dans les normes MPEG1, MPEG2, H.264 et d'autres normes.De la figure, nous pouvons voir que l'image d'entrée actuelle doit d'abord être divisée en blocs, le bloc de l'image obtenue par le bloc doit être soustrait du image prédite après compensation de mouvement pour obtenir l'image de différence x, puis une transformation DCT et une quantification sont effectuées pour le bloc d'image de différence. Les données de sortie quantifiées ont deux emplacements différents: l'un est de les envoyer au codeur d'entropie pour le codage, et le flux de code codé est sorti dans une mémoire cache Enregistrer dans l'appareil et attendre la transmission. Une autre application consiste à contre-quantifier et inverser le changement du signal x ', qui ajoute la sortie de bloc d'image avec compensation de mouvement pour obtenir un nouveau signal d'image de prédiction, et envoie un nouveau bloc d'image de prédiction à la mémoire de trame.



|
|
|
|
Dans quelle mesure (long) le couvercle du transmetteur?
La portée de transmission dépend de nombreux facteurs. La distance réelle est basée sur l'antenne d'installer la hauteur, le gain de l'antenne, en utilisant l'environnement comme la construction et d'autres obstacles, la sensibilité du récepteur, l'antenne du récepteur. Installation de l'antenne plus élevée et l'utilisation dans la campagne, la distance sera beaucoup plus loin.
Transmetteur FM 5W Exemple d'utilisation dans la ville et ville natale:
J'ai une utilisation par le client 5W émetteur fm USA avec antenne GP dans sa ville natale, et il le tester avec une voiture, il couvre 10km (6.21mile).
Je teste l'émetteur fm 5W avec antenne GP dans ma ville natale, il couvre environ 2km (1.24mile).
Je teste l'émetteur fm 5W avec antenne GP dans la ville de Guangzhou, il couvre environ seulement 300meter (984ft).
Voici la gamme approximative de différents émetteurs de puissance FM. (La plage est de diamètre)
Transmetteur FM 0.1W ~ 5W: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
Transmetteur FM 15W ~ 80W: 3KM ~ 10KM
Transmetteur FM 80W ~ 500W: 10KM ~ 30KM
Transmetteur FM 500W ~ 1000W: 30KM ~ 50KM
Transmetteur FM 1KW ~ 2KW: 50KM ~ 100KM
Transmetteur FM 2KW ~ 5KW: 100KM ~ 150KM
Transmetteur FM 5KW ~ 10KW: 150KM ~ 200KM
Comment nous contacter pour l'émetteur?
Appelez-moi + 8618078869184 OU
Envoyez-moi un courriel [email protected]
1.How loin que vous voulez couvrir de diamètre?
2.How haut de la tour vous?
3.Where êtes-vous?
Et nous allons vous donner plus de conseils professionnels.
À propos de nous
FMUSER.ORG est une société d’intégration de systèmes spécialisée dans la transmission sans fil RF / équipement audio vidéo / de studio / streaming et le traitement de données. Nous fournissons tout ce que vous souhaitez, du conseil au conseil en passant par l’intégration en rack, l’installation, la mise en service et la formation.
Nous proposons des émetteurs FM, des émetteurs de télévision analogique, des émetteurs de télévision numérique, des émetteurs VHF UHF, des antennes, des connecteurs de câble coaxial, STL, Traitement en direct, Produits de diffusion pour le studio, Surveillance du signal RF, Encodeurs RDS, Processeurs audio et Unités de contrôle de site distant, Les produits IPTV, encodeur / décodeur vidéo / audio, sont conçus pour répondre aux besoins des grands réseaux de diffusion internationaux et des petites stations privées.
Notre solution comprend une station de radio FM / une station de télévision analogique / une station de télévision numérique / un équipement de studio audio vidéo / une liaison d'émetteur de studio / un système de télémétrie d'émetteur / un système de télévision d'hôtel / une diffusion en direct IPTV / une diffusion en direct en continu / une conférence vidéo / un système de diffusion CATV.
Nous utilisons des produits de technologie de pointe pour tous les systèmes, car nous savons que la fiabilité et les performances élevées sont essentielles pour le système et la solution. Dans le même temps, nous devons également nous assurer que notre système de produits a un prix très raisonnable.
Nous avons des clients de diffuseurs publics et commerciaux, d'opérateurs de télécommunication et d'autorités de régulation, et nous proposons également des solutions et des produits à des centaines de diffuseurs plus petits, locaux et communautaires.
FMUSER.ORG exporte depuis plus de 15 ans et a des clients partout dans le monde. Avec 13 ans d'expérience dans ce domaine, nous avons une équipe professionnelle pour résoudre toutes sortes de problèmes du client. Nous nous sommes engagés à fournir des prix extrêmement raisonnables de produits et services professionnels. Email du contact : [email protected]
Notre Usine

Nous avons modernisation de l'usine. Vous êtes invités à visiter notre usine lorsque vous venez en Chine.

À l'heure actuelle, il existe déjà clients 1095 partout dans le monde visité notre bureau de Guangzhou Tianhe. Si vous venez en Chine, vous êtes invités à nous rendre visite.
Au Salon

Ceci est notre participation à 2012 Global Sources Hong Kong Electronics Fair . Les clients de partout dans le monde enfin avoir une chance de se réunir.
Où est Fmuser?
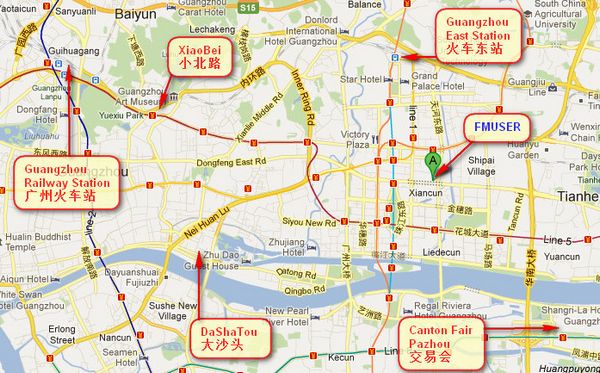
Vous pouvez rechercher ces numéros " 23.127460034623816,113.33224654197693 "dans google map, vous pouvez trouver notre bureau fmuser.
bureau FMUSER Guangzhou se trouve dans le district de Tianhe, qui est le centre du Canton . Très près à la Foire de Canton , gare de guangzhou, route Xiaobei et Dashatou , seul besion 10 minutes si prendre TAXIS . Bienvenue amis partout dans le monde à visiter et à négocier.
Contact: Blue Sky
Mobile: + 8618078869184
WhatsApp: + 8618078869184
WeChat: + 8618078869184
Courriel : [email protected]
QQ: 727926717
Skype: sky198710021
Adresse: No.305 Chambre Huilan bâtiment No.273 Huangpu route Guangzhou Chine Code postal: 510620
|
|
|
|
Français: Nous acceptons tous les paiements, tels que PayPal, carte de crédit, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer, si vous avez des questions, veuillez me contacter [email protected] ou WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Nous vous recommandons d'utiliser Paypal pour acheter nos articles, Le Paypal est un moyen sûr d'acheter sur Internet.
Chaque de notre liste d'articles en bas de page sur le dessus ont un logo paypal pour payer.
Carte de crédit.Si vous ne disposez pas paypal, mais vous avez la carte de crédit, vous pouvez également cliquer sur le bouton jaune PayPal pour payer avec votre carte de crédit.
-------------------------------------------------- -------------------
Mais si vous avez pas une carte de crédit et ne pas avoir un compte paypal ou difficile à obtenu un accout paypal, vous pouvez utiliser ce qui suit:
Western union.  www.westernunion.com www.westernunion.com
Paiement par Western Union à moi:
Prénom / Prénom: Yingfeng
Nom / Prénom / Nom de famille: Zhang
Nom complet: Yingfeng Zhang
Pays: Chine
Ville: Guangzhou
|
-------------------------------------------------- -------------------
T / T. Payer par T / T (virement / transfert télégraphique / Virement bancaire)
PREMIÈRES INFORMATIONS BANCAIRES (COMPTE COMPTE) :
SWIFT BIC: BKCHHKHHXXX
Nom de la banque: BANK OF CHINA (HONG KONG) LIMITÉE, HONG KONG
Adresse de la banque: BANK OF CHINA TOWER, 1 GARDEN ROAD, CENTRAL, HONG KONG
CODE DE LA BANQUE: 012
Nom du compte: FMUSER INTERNATIONAL GROUP LIMITED
N ° de compte. : 012-676-2-007855-0
-------------------------------------------------- -------------------
Deuxième RENSEIGNEMENTS BANCAIRES (COMPTE) :
Bénéficiaire : Fmuser International Group Inc
Numéro de compte: 44050158090900000337
Banque du bénéficiaire : succursale de la China Construction Bank Guangdong
Code SWIFT : PCBCCNBJGDX
Adresse : NO.553 Tianhe Road, Guangzhou, Guangdong, district de Tianhe, Chine
** Remarque : lorsque vous transférez de l'argent sur notre compte bancaire, veuillez ne rien écrire dans la zone de remarque, sinon nous ne pourrons pas recevoir le paiement en raison de la politique du gouvernement sur le commerce international.
|
|
|
|
* Il sera envoyé en 1-2 jours ouvrables lorsque le paiement clair.
* Nous vous enverrons à votre adresse paypal. Si vous voulez changer l'adresse, s'il vous plaît envoyez votre adresse et le numéro de téléphone à mon email [email protected]
* Si les paquets est inférieur à 2kg, nous sera expédiée par la poste aérienne, il faudra environ 15-25days à votre main.
Si le paquet est plus que 2kg, nous expédions par EMS, DHL, UPS, Fedex livraison rapide express, il faudra environ 7 ~ 15days à votre main.
Si le paquet plus 100kg, nous vous ferons parvenir par DHL ou fret aérien. Il faudra environ 3 ~ 7days à votre main.
Tous les paquets sont la forme la Chine guangzhou.
* Le colis sera envoyé comme un "cadeau" et déclear le moins possible, l'acheteur n'a pas besoin de payer pour la "TAXE".
* Après bateau, nous vous enverrons un e-mail et vous donner le numéro de suivi.
|
|
|
Pour la garantie.
Contactez-nous --- >> Renvoyez-nous l'article --- >> Recevez et envoyez un autre remplacement.
Nom: Liu xiaoxia
Adresse: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou en Chine.
Code postal: 510620
Téléphone: 8618078869184 XNUMX XNUMX XNUMX XNUMX
S'il vous plaît revenir à cette adresse et écrivez votre paypal adresse, nom, problème sur la note: |
|













